
WebRTC Pong
12 Dec 2021Progress: Complete
This project is both a look at newfangled WebRTC possibilities and a deconstruction of video game netcode.
➤ To play the game, head to mitxela.com/pong
Scroll down for a detailed explanation of how it works, or, for a spoken overview watch this video:
Intro
STUN, TURN, and WebRTC are duct tape technologies. Band-aids over bandages over band-aids. They're here to fix problems introduced by previous fixes.The previous fix in question is of course the widespread adoption of NAT (Network Address Translation), the "solution" to IPv4 address space exhaustion. NAT squeezed the internet into its web-centric form, with clients requesting web pages but if you wanted to do anything else it meant fiddling around with port forwarding.

No one actually cares what all these acronyms stand for, but for the sake of completeness:
- WebRTC: "Web Real-Time Communication"
- STUN: "Session Traversal Utilities for NAT"
- TURN: "Traversal Using Relays around NAT" (the fallback if STUN fails)
- SDP: "Session Description Protocol"
- ICE: "Interactive Connectivity Establishment" (don't ask)
- UPnP: "Universal Plug and Play" (and the award for Least Descriptive Name goes to...)
UPnP is one of the ways around NAT, but it's poorly supported and is generally just horrible. The rise of video calling led to a new demand for easy peer-to-peer connections, in-browser. Enter UDP Hole Punching, a technique as disgustingly beautiful as the NAT it's trying to traverse. The whole concept of "Hole Punching" brings the insanity full-circle.
But despite how cynical I may sound, let me just say that Hole Punching is awesome. I don't care about video calls, I care about video games. Having a decent, predictable, fairly reliable way of establishing peer-to-peer connections via a matchmaking server is a godsend to indie game developers. I spent most of my teenage years making games, and port forwarding was always a huge thorn in our side. Sure, you could configure your little game to work on one network and play it with friends, but if you wanted it to take off – if you wanted strangers to play it – you had to kiss goodbye to peer-to-peer and run a server.
I take it back. STUN isn't duct tape, it's WD-40. It frees up the sticking points and greases the internet back into a shape that almost works the way it was intended to.

Bare bones
When I want to learn about a new technology the nicest way is to try and build the smallest, simplest working prototype using it. A while back, I attempted just that, creating a very simple chat program.(At the time, there were not many examples or tutorials available, but in the last couple of years a lot more tutorials have sprung up. Recently, a nice website has appeared called WebRTC for the Curious, which goes into detail about how the underlying tech works.)
In order to establish a connection between browsers, a charade has to take place. Each browser has to figure out how its local network is going to be traversed, and then exchange info with the other side.
- The web server, naturally, serves the web pages, that is the Javascript and HTML code.
- The "signal server" is the method by which the browsers can pass information to each other before the connection is established. Normally the webserver is also the signal server, but it doesn't have to be. In fact, you could simply display the ICE and SDP information as a block of text, and have the users share connection info over email.
- The STUN server uses the STUN protocol to establish and enact the hole punching. This is a very simple process if all goes well, but as it involves lower-layer networking concepts, STUN is outside of the scope of most webservers. However, because the bandwidth involved is almost nothing, there are plenty of free STUN servers we can use. In these examples I use both
stun.stunprotocol.organdstun.l.google.com. - A TURN server is a relay server, used if the hole punching fails. Since the entire bandwidth of the connection has to be bounced off the relay server, naturally there are no free TURN servers. I don't care about TURN – if it isn't going to be peer-to-peer, then there are much better ways of going about this, such as websockets to a dedicated server.
The server hosting this webpage uses Apache, PHP and MySQL. Virtually no-one would voluntarily want to create the signal server using these technologies, but since that's what I have to work with it's what I'll do. Sending messages between browsers is dead simple with a persistent process like node, but here we're going to have to stick each message in a MySQL table and ajax-poll for it at the other end.
The connection process goes like this:
- We implement some method of identifying the other browser. In my case, I'll let one person "host" and give them an ID to share with the other person. When they enter the ID, the session can begin.
- The browsers call
new RTCPeerConnection()and wait for ICE candidates. Each ICE candidate is a possible method of traversing the NAT, and it may take a few seconds to identify all of them. Each ICE candidate should be sent to the other browser via the signalling server. - One of the browsers, the host, creates an "offer" and generates an SDP string, which is sent to the other side via the signalling server.
- The other browser creates an answer to this offer, and sends it back to the host via the signalling server.
- When the host processes the answer, everything is in place, and the direct connection should magically open.
My PHP code is as simple as it could possibly be, just to send a message from one browser to the other. For my bare bones implementation, I found I was able to skip the ICE candidate sharing entirely. It seems the SDP string contains a summary of the ICE candidates gathered so far, so if you merely wait until all candidates have been gathered before sending the SDP message, the process will still work. This limits the required amount of signalling down to a single message and response.
A chat system was born!
I admit it doesn't make for the most visually interesting screenshot, but it marked the beginning of our journey.
While this chat system worked, it definitely wasn't perfect. Most annoyingly, sometimes the connection simply failed to establish (often with a completely unhelpful error message, but usually with no error message at all).
Possibly the most irritating part of all this is the difficulty in testing. To test properly, we would need to run our code on multiple internet connections and on at least all the different types of NAT. It's not clear if different STUN servers have different reliability, or if reconnecting repeatedly might saturate the NAT cache, or if Chrome/Firefox compatibility is flaky, or if my shortcut of skipping the explicit ICE candidate sharing was a stupid idea. As with most experimental technologies, the protocol and implementations are updated at an alarming pace, so sometimes the solution is to simply wait a few months for the problems to fix themselves.
Attempt 2
About two years later, I came back to this project to see if the reliability had at all improved. Disappointingly not, so I decided to at least fix the one thing we were obviously doing unconventionally – not sharing the ICE candidates properly. All of the examples use something called "Trickle ICE" which means sending each candidate to the other side the moment it's discovered. The benefit of Trickle ICE is that the connection can establish more quickly than if we wait for all of them before signalling.So I rewrote the chat program, this time signalling all the ICE candidates properly.

Did it make a difference? Not in the slightest! The connection failed to establish maybe one in five times, with no apparent reason, just like before.
The reason for this lack of reliability eventually turned out to be a trivial mistake in my code, which I didn't spot until later, but I may as well explain here. The SDP string is being shared via an ajax POST request. The SDP string itself is wrapped in JSON, but essentially it's just a list of keys and values. An example SDP looks something like this:
v=0 o=- 3816404294120614953 2 IN IP4 127.0.0.1 s=- t=0 0 a=group:BUNDLE 0 a=extmap-allow-mixed a=msid-semantic: WMS m=application 9 UDP/DTLS/SCTP webrtc-datachannel c=IN IP4 0.0.0.0 a=ice-ufrag:Lrjm a=ice-pwd:bH6gjgudue7gV7vLuBYVV/Yl a=ice-options:trickle a=fingerprint:sha-256 EE:69:A7:8A:AA:44:C5:1F:3D:FF:89:36:87:6E:92:A0:B5:1C:EC:EC:8A:0A:2F:B0:70:11:5E:B7:C9:ED:4C:DA a=setup:active a=mid:0 a=sctp-port:5000 a=max-message-size:262144
Notice that the ICE password is a base64-encoded value. With careful logging, I suddenly noticed that occasionally there would be a space in the password. As soon as I spotted that, I knew what the problem was.
For the ajax POST data, I had used encodeURI() instead of encodeURIComponent(). The only relevant difference is that with the former, a plus sign will not be escaped. In GET/POST form data, a plus sign is used to represent a space. Since the rest of the SDP string was escaped correctly, and the randomly-generated base64 string only sometimes contained a plus sign, the system worked fine most of the time, only occasionally the passwords wouldn't match.
Happily, fixing this fixed all of the reliability problems we had before.
File Transfers
In the process of investigating the reliability problem, I figured I would maintain enthusiasm by fleshing out my chat program.We can choose if the data connection is ordered and reliable, or unreliable and out-of-order, for the benefit of potentially lower latency. For a video call, the latter is obviously more useful, compared to the chat program where lost messages are undesirable.
I upgraded the chat program to share files by drag & drop. The file has to be serialized and transmitted in fairly small chunks, say around 64kB. Sending a large file in a peer-to-peer manner turns our toy chat system into an actually useful tool, but a lot of tedious work needs to be done for big files. The javascript FileSystem API, which I've used successfully in the past, is apparently deprecated now, so the simplest way to provide a file download is just to make a data URL. This has the disadvantage of building a long string of the whole file in ram, so it isn't practical for big files really, but I also acknowledge that this is just for playing around. For transferring big files, better programs/sites exist.
I read the file as a binary string at one end, and cut it into chunks so that the base64 of each chunk is less than 64kB. If we make each chunk size a multiple of 3 bytes, that means we can directly concatenate the string together at the other end, so the whole thing ends up very simple.
Once again, a screenshot doesn't really do the program justice. If you are interested in playing with these early prototypes, they are mostly still there at the start of the git history for the repo. Incidentally, while that drag & drop shot is regrettably from Windows, if you have a linux machine with as broken a set-up as I do, with no graphical file manager, I can strongly recommend a utility called dragon that gives you the bare minimum to interact via drag & drop. It's invaluable for testing this sort of thing in a setup where you don't want to install hundreds of megabytes of bloated desktop software that you'll never use again. Ahem.
With that task pointlessly out of the way, it was time to advance to the main event, WebRTC Pong.
Netcode
When I play online games, I have a habit of idly wondering about how their netplay code is implemented. Sometimes it's more obvious than others. Disclaimer: Pretty much everything that follows is from my own musing about the problems, and may be partly or entirely incorrect or irrelevant.A multiplayer first-person shooter game like TF2 has a simple server-client model. The server is in charge and the arbitrator of everything. Each player's input directly controls their character's movement, and a message is periodically sent to the server containing their coordinates and heading. The server collates these numbers and distributes them to everyone else. Each client can then plot the other characters in their positions, and if there's lag for some of them, we just assume they stay on the same heading until told otherwise (or they time out).
The result is that there's no lag at all in our own movement (until the connection gets bad enough for the server to tell us otherwise) and other characters mostly look right, occasionally teleporting a little when they lag.
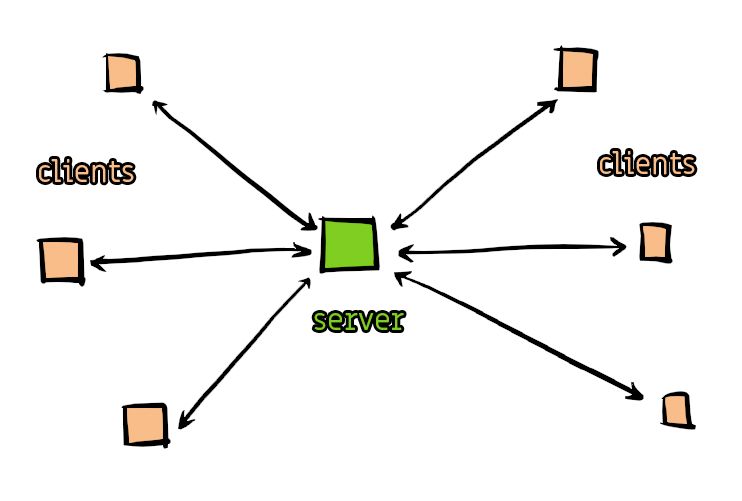
For a two-player fighting game, it's still possible to do it this way but peer-to-peer makes much more sense, as the connection should be faster and doesn't require the cost of running a server.
The simplest (and definitely the worst) way of doing a peer-to-peer arrangement is to simply make one of the players the server. In 2006 I made a very stupid simple game called LEGO PONG. Not only did one person need to enable port forwarding, but the host had a distinct play advantage, as the ball position never lagged for them. The other player had to put up with not just a jittery ball position, but their display of the game was essentially delayed by the ping time between players.
I don't actually have a screenshot, but here's a sample of the graphics it had:

Lego pong needed a low ping.
Having one player be the server is not inherently bad (in fact, it's often unavoidable) but naive netcode like this is simply unacceptable. The only system that's fair is to ensure that both players see the same thing at the same time. Another problem is that as the complexity of the game grows, having the server send the full state of the game to the client becomes unviable.
A much, much better way to do it is to have an input buffer. Any inputs you make are delayed by a few frames before they take effect. At the same time, the inputs are sent to the other player, so by the time the delay has elapsed, both players have full knowledge of each other's movements. Not only is this much more fair, but sending only the inputs uses far less bandwidth than syncing game data.
At the risk of rambling, in 2008, we created a fan game called Zelda Bomberman (although Atrius did all of the work).
There's still a video on youtube of it, although it's an early version of the game and more was added/fixed later. We never did get around to adding the hookshot though.
There were two "aha!" moments during the development of Zelda Bomberman for me. One is that although the levels are randomly generated, there is no need to send any level data from server to clients. The only thing we need to send is the random seed – and from there, all the clients use the same algorithm to generate the level and they'll end up with exactly the same result. The whole level, no matter how complicated, is compressed into a single 32-bit number!
The second "aha!" moment was that when we logged the network traffic for debug purposes, we realized it contained everything needed to replay the whole match. That 8-minute youtube video was generated by Atrius as an afterthought, just from maybe a few hundred kilobytes of traffic. My mind was blown!
You would think that if a couple of teenagers can manage to produce working netcode, then the professionals should have no problem with it. Not so, when it comes to Super Smash Bros. To be fair, the game is so twitchy that if you'd asked me a few years ago if netplaying Smash was even possible, I'd have said no, since even the slightest lag or input delay would be jarring. But Smash Online was made, and the gameplay ranges from "just about OK" to "utterly, appallingly dreadful".
A friend of mine insists that it's still fair, because the lag is symmetrical. Even if that were the case, the careful balance between different characters and abilities goes out the window when the input delay is that much, and the best tactic seems to be to just play as the heaviest characters and stomp on everyone (which, ordinarily, would not be viable, since, ordinarily, they would be able to react).
The story doesn't end here. But while wading through the laggy matches, I've spent plenty of time wondering about how their netcode is implemented, and whether it truly is symmetrical, and whether I could do better. The concept of "WebRTC Pong" was to build a toy version of an online game, and see just how difficult it is to get the gameplay to be fair and symmetrical.
Pong Time
The very first thing to do is separate the game logic "frames" from the drawing frames of the display. For smooth animations, we should use the browser'srequestAnimationFrame(), but only to draw the scene as it currently exists. The game logic itself must go into separate setTimeout() calls. The main reason is that (unlike on the Switch) each client's display might be running at a different framerate.
Timing in javascript is notoriously unreliable. setTimeout treats the "milliseconds" value you pass it as a polite request, at best, but worse than that, most of the timing functions are intentionally hobbled for security reasons. The performance.now() call, which is supposed to give you the most accurate timestamp, will be quantized by the browser to prevent fingerprinting. A whole bunch of timing exploits allow programs to escape the sandbox, and for now, all we can do is take away the toys.
Security-conscious browsers quantize performance.now() to the nearest 100ms, and in that case, we have no hope of running the game and might as well give up. Most browsers quantize to 1ms, which is acceptable. And while individual measurements might be inaccurate, the long term average should be pretty good. If we save a timestamp at the first frame, and each frame advance this timestamp by the exact frame period, choosing a delay for setTimeout based on that, it should average out the jitter.
One other thing I should mention – browsers will limit setTimeout calls when a tab is minimised or unfocused. The limit is usually one call per second, so if the tab is unfocused the game will slow to a halt. You can get around this by placing the code into a webworker, which isn't subject to the same restrictions, but I have no interest in doing so, since the only reason to keep the game running in the background would be to waste bandwidth. It's also pretty useful as a quick way to simulate lag (more on that later).
Aside: Ordered & reliable & predictable
We have a choice between an ordered, reliable connection or an unreliable, possibly unordered, but lower latency connection. WebRTC is entirely over UDP, and the ordered, reliable connection is handled not by TCP but the similar RTP ("Real-time Transport Protocol") and RTCP ("Real-Time Transport Control Protocol"). If we were hoping to make the lowest-latency system possible, the unreliable transport would be the obvious choice. The input data is generally small enough that we could add plenty of redundancy to each packet without crossing the MTU threshold, for instance by repeating the inputs for the last few frames in each packet.However, since this is a toy example, to keep things simple I stuck with the reliable transport.
I should also mention that the WebRTC connection is encrypted. This adds some CPU overhead, but shouldn't add any network overhead.
In terms of predictability, it's easy enough to drop in a pseudo-random number generator, but I did have a concern about the use of floating point numbers. We use trigonometry and floating point multiplications to handle the ball's motion, but it's not clear if these calculations will give the exact same answers on different architectures. Some processors may use different techniques to calculate the trigonometric values. The floats are all 64-bit, so it would take a long time for these errors to add up, but if a match lasted long enough perhaps it would go out of sync. Only time will tell.
Buffers
The concept of delay-based netcode is as follows.As mentioned before, we make the game completely deterministic, so the only things that needs to be shared over the network are the player's inputs, and the initial seed for the random number generator.
We have two buffers, one for our inputs, and one for the opponent's. Each frame, we record our input in the buffer, send a copy to the other side, and, assuming the buffers are not empty, consume inputs from the other end of the buffers. The size of the buffers will determine the input lag. So long as this input lag is bigger than half the ping time, the buffers should never run empty.
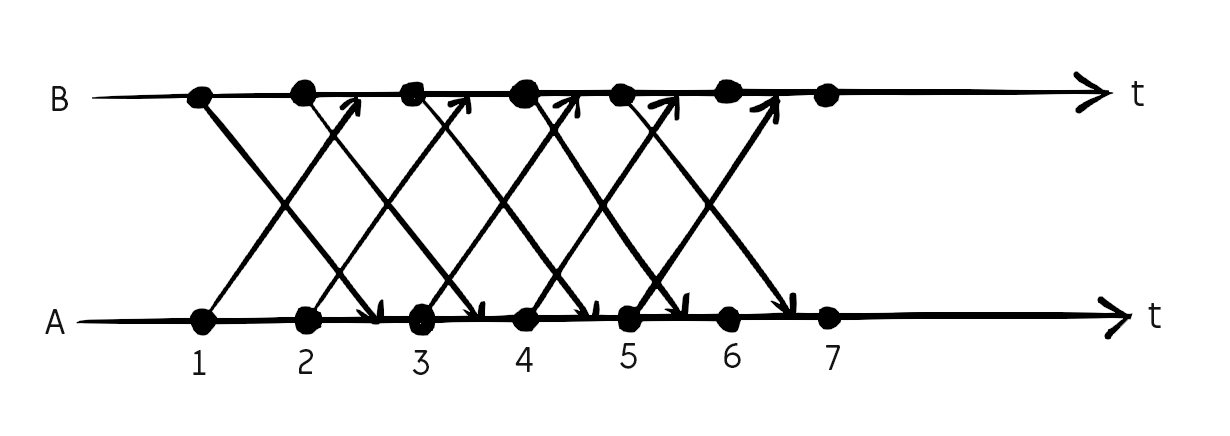
Each packet might take more than a frame to reach the other side, but by intentionally delaying the effect of the inputs, both sides can run in sync.
Frame Timing
The next challenge is to make sure each frame is shown at the same time at each end. We can synchronize the start of the game by first measuring the ping time (a round trip) ...
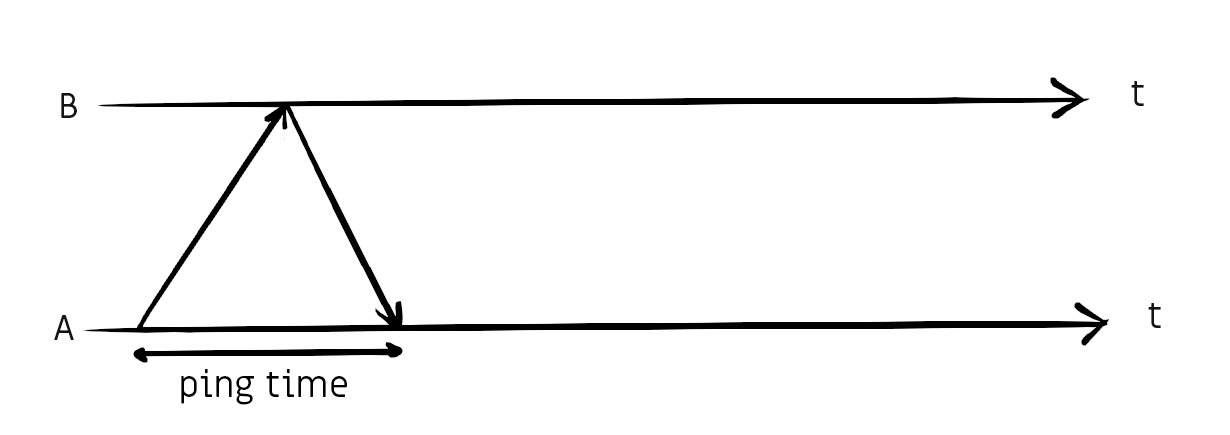
... then sending the "start" command to the other side while waiting half the ping time before starting ourselves.
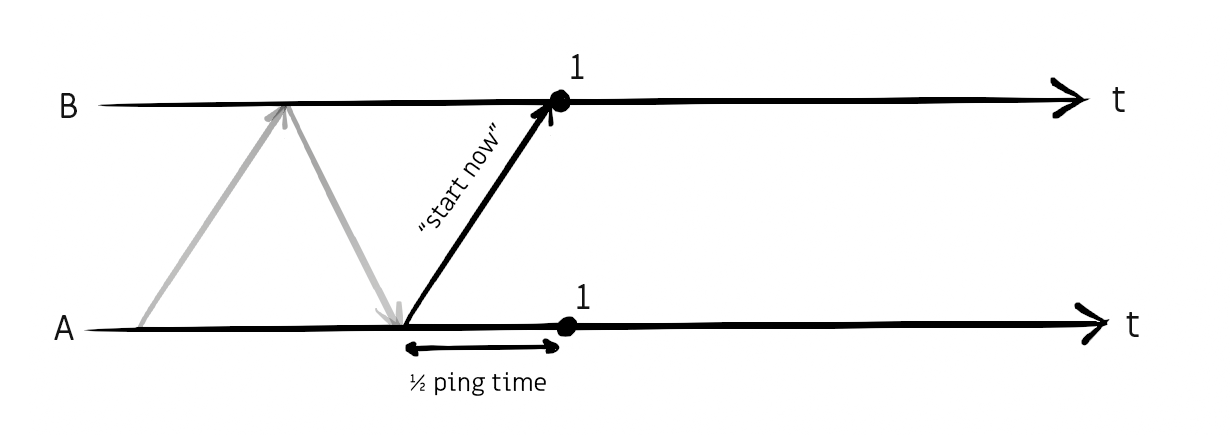
From then on, each frame will happen every frame period (16.67ms at 60FPS).
All well and good, but very soon the frames will drift apart from each other so a continuous synchronization is needed.
The result of performance.now() is usually the number of milliseconds since the page was loaded. You can convert this into an absolute (unix) timestamp using the non-standard performance.timeOrigin but the idea that both computers' internal clocks will be synchronized to within even tens of milliseconds is laughable. It's not uncommon for computer clocks to be out by several minutes. But if we're clever about this, we don't even need to synchronize clocks.
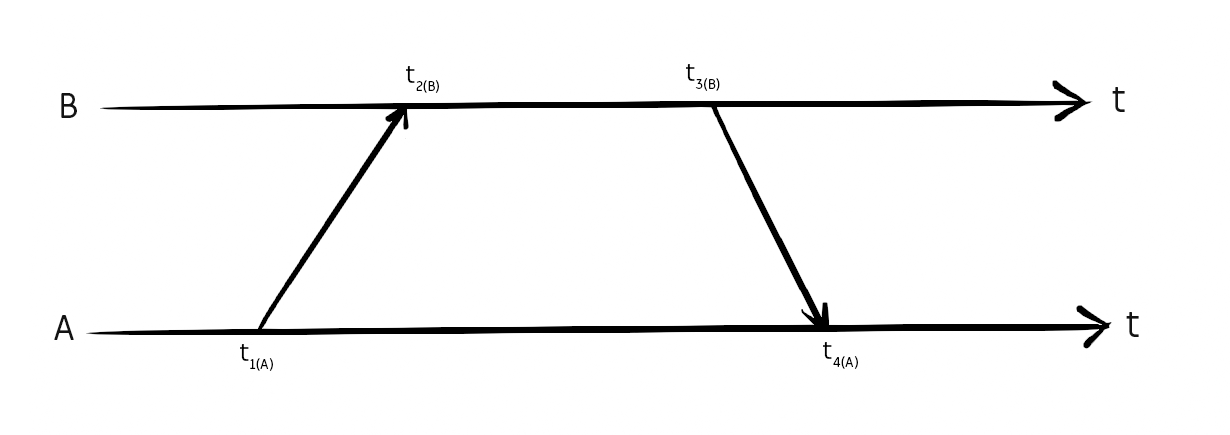
Since the reference clocks of A and B might be wildly different, calculating (t2 - t1) is meaningless, it might give an answer of ten seconds, or minus five minutes. But the difference between t3 and t2 is exact, and the difference between t4 and t1 is exact, so from that we can calculate the ping time. By appending a time pair onto the end of every packet we send, the ping time can be calculated from any two packets, even if there were other packets in-between.
Finally, we append to each packet an estimate of when the next local frame will occur. When that packet arrives, we can use that estimate, along with the ping time, to calculate if our frames are happening too soon or too late.
With the lag/lead time measured, in order to correct for it I built a control loop. The first decision was to only ever delay frames, not advance them. This might not have been necessary, but I was worried about stability. If we only ever correct in one direction, then only one side will be trying to correct at any given moment. If both sides try to correct at the same time, it has a high risk of oscillation. Speaking of oscillation, my initial control loop oscillated wildly so this seemed like the right moment to start plotting some graphs.
The graphs were plotted very quickly, I apologise for being too lazy to add units or labels, but the absolute values don't matter at all. All the matters is the shape of the graph.
Our control loop consists of a proportional correction factor (e.g. for a correction factor of 0.5, if we are leading by 10ms, then delay by 5ms), an averaging period for ping and lead times (and the longer the averaging period, the more gentle the correction factor needs to be), and finally a threshold, below which we don't bother to correct timings (I set this to 1 millisecond, since that matches our timer resolution, trying to correct beyond that would be silly).
By minimising the tab, we can intentionally cause a massive discrepancy in the frame timing as the setTimeout calls are throttled, then watch as the control loop tries to correct for it.
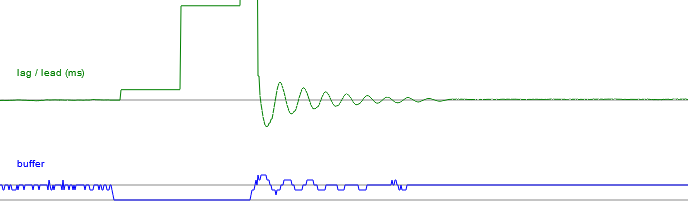
The overshoot is kind of hilarious, but the system works!
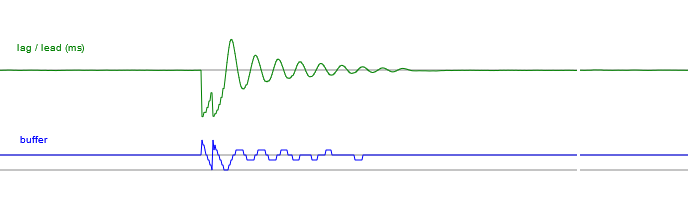
When the graph is positive, one client is doing the correction, and when it's negative the correction is done by the other client. The horizontal axis is one pixel per frame, so that took a few seconds to settle. If we tweak our numbers until the system is critically damped, it should settle in a fraction of a second.
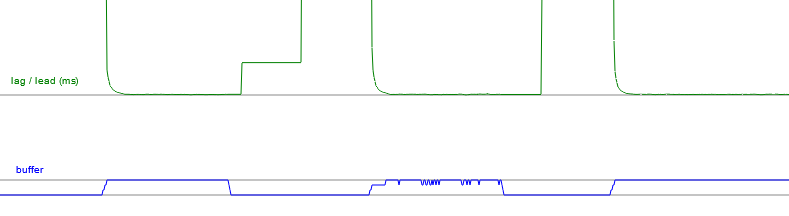
Note that in this case, where the tab has been minimised, one player has completely missed out on a number of frames, and the other player has to run the game in slow motion to equalize. In an actual match with network lag, both clients will be trying to run at full speed, with just the packets delayed.
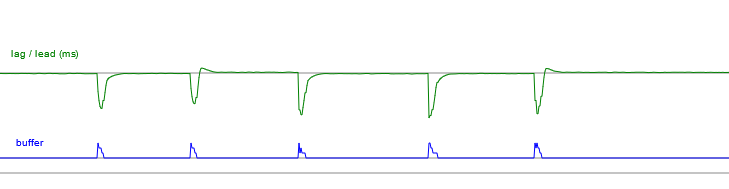
I first used my phone's mobile data connection to simulate a laggy connection, which works (you can even increase the ping time by wrapping your hands around the phone's antenna) but for a more scientific approach there are a number of tools that can simulate network conditions. tc / netem is one such utility, another one for Windows with a GUI is clumsy.
There is still something satisfying about playing it on my phone with "real" network conditions though. With the control loop working, both devices display the same thing at the same time (excepting the differences in display latency) and you can play the game looking at either screen.
Note: since the game is 60FPS and this video was also filmed at 60FPS, there may well be interference effects in the footage.
Animation frame sync
It became obvious that my phone was running at 59.78Hz, my laptop was running at 59.54Hz, and my desktop was running at exactly 60Hz. It's not unheard of to have a monitor run at 50Hz. There might even be some elitist jerks out there running their monitors at 75Hz (they're a lost cause).When playing against yourself (yeah, I know) with both browsers on the same machine, the animation frames will always be in sync. This means that for the most part, the game plays perfectly, but by repeatedly minimising and un-minimising the tab we can randomise the alignment between game frames and animation frames. Occasionally, the resumed game would stutter like hell, barely scraping along at 30FPS until the tab was refocused once more. During this stuttering, my plot of the buffer size also showed bizarre instability.

requestAnimationFrame reports a timestamp in the same units as performance.now() so it's easy to calculate the exact frame timing difference (which I call framesync) and plot it on another graph. Here we have four plots, with the framesync value in orange. During regular play between two browsers on the same machine, the framesync value is a solid horizontal line, except for the instability that can be induced occasionally by minimising and un-minimising like this.
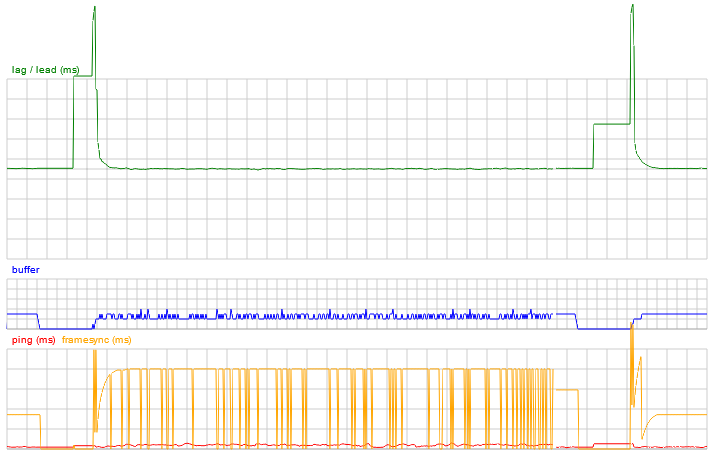
The reason for the instability is that the setTimeout calls were asking for the game logic to be processed at exactly the same time as the animation frames. Due to browser and OS jitter, it was pretty much random which one would get processed first, so instead of nicely alternating between game frames and animation frames, we would get two game frames, then two animation frames, and so on. The game logic was still rock solid (if you could put up with the reduced framerate), the only reason the buffer appears to be unstable is that the statistics are calculated at the animation frame. So if the animation frame happens immediately after the game frame, the buffer appears to be smaller than if it happens immediately before.
In the real-world scenario of two machines with marginally different frame rates, the sync between game frames and animation frames is constantly drifting. As it approaches this region, the game begins to stutter, then recovers as the frame sync drifts apart again.
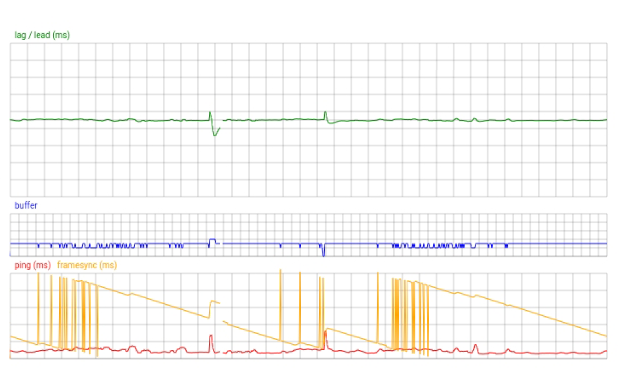
The natural progression is to attempt to detect and correct for this problem. The fix is a bit finickity, we need to add a delay between the game frame and the animation frames, but not in such a way that it affects the game timing or the netcode synchronisation we worked so hard on. The delay needs to be toggled on when we approach the instability region, and toggled off when we're safe. For the sake of the netcode, we need to pretend that the delay isn't there.
I named this correction "synctick" and it can be plotted too.
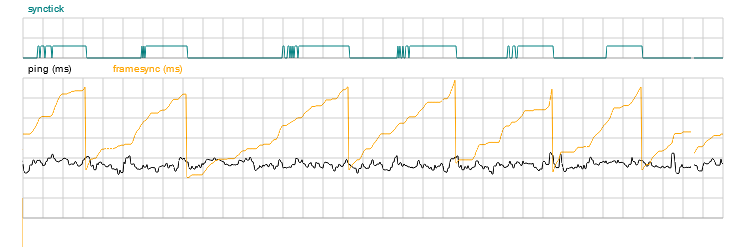
Here we've induced a serious drift in the framesync by adding network lag. The framesync (orange line) does a sawtooth, but each transition is perfectly clean, minimising the number of dropped frames. You can see that the synctick value (teal) toggles on and off as the framesync approaches the instability. The synctick suffers instability as we approach the threshold for it, but this is expected and not an issue. The delay we're adding due to synctick is only 4ms, a quarter of a frame, so its affect on the game logic is negligible.
While we're here, we can configure our monitor for 75Hz and see how it behaves.

As I said, it's a lost cause. It doesn't look that bad to play like this, but it definitely isn't smooth. I suppose if both players were running at 75Hz, we could configure the game logic to run at 75Hz too, but that's beyond the scope of my toy pong.
Rollback
"rollback" netcode means making a prediction for what the other player did, and correcting – if necessary – when what they really did becomes known.You might think rollback netcode for a game of pong is overkill, but the whole point of this project was to learn about it. There are multiple approaches to implementing rollback netcode, here is the one that I took.
Starting from our delay-based code, we choose a small buffer size. When the buffer runs out, instead of waiting for more packets to arrive, we:
- Take a save state of the game. This includes player positions, ball position, scores, and the seed for the random number generator
- Make up some inputs and pretend that's what the other player did. Normally we would repeat whatever their last inputs were, because statistically that's most likely the case. With our mouse-controlled pong, this isn't that good of a guess, unless they're not moving at all, but it doesn't matter because the prediction doesn't need to be spot-on.
- Continue as normal. While in this rollback mode, we continue to make up inputs for the opponent, getting further and further away from that save-state of the last true state of the game.
When packets finally arrive, containing the now historical data of what the opponent did, we need to quickly go back and correct for it. We load the save state, and then instantly replay all of the inputs that we now know for certain.
If we have enough data to return to the present, then great, but if not, we update the save-state with the new true state of the game, and then run the predictions forwards again until we reach the current frame.
The overall effect is that the game will play exactly the same as if all the inputs had arrived instantly, with no drops in framerate. Locally, our paddle movement is spot-on, and the ball movement is perfectly smooth. The opponent also sees both their paddle and the ball to be perfectly smooth. The only sign that there's any lag at all is the occasional jitter in the other person's paddle. But even with huge lag, if they manage to hit the ball back in their local game, then the rollback will update to show that.
The whole idea of rollback netcode is remarkably simple, compared to all the hassle we went through to get here. By combining the delay-based and rollback netcode like this, we've essentially built a hybrid netcode with elements of both.
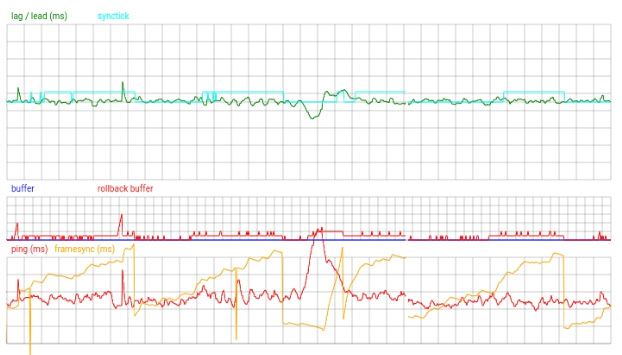
One problem is that for a game more complicated than pong, saving and loading the game state, and re-running multiple frames instantly, could consume a lot of CPU power. Though I haven't researched this, I suspect most "real" rollback systems go to great lengths to optimise the process. For starters, if our predictions turned out to be correct, it obviously isn't necessary to re-run the game logic. It may also be that if the game logic is designed with this in mind, we don't need to form a complete save-state of the game, merely iterate the inputs backwards and forwards again.
Conclusion
I've put the source code to WebRTC Pong on the github page.My reason for first experimenting with WebRTC was part of swotGB, my gameboy emulator, in the hope of being able to trade pokemon in-browser. Emulating a gameboy link cable is a whole different affair, and whether it would work is dependent on the game. The link cable even on the original gameboy has quite a high bandwidth and very little latency, and games may or may not be able to cope with lag.
The best way to enable the link-cable over a network is of course to emulate two gameboys – then the problem devolves into the one we solved earlier. There could be megabytes going back and forth between gameboys, but if both are emulated at both ends, then the only thing that needs to traverse the network is the player's inputs.
This concept was been taken to its logical extreme only a few months ago with the new integrated-mGBA update for Dolphin emulator.
For context, Zelda Four Swords Adventures is one of the hardest games to emulate, even forgetting netplay. It was one of the few games (along with Crystal Chronicles) that made full use of the Gameboy Advance to Gamecube link cable support. For four-person multiplayer, you needed a Gamecube and four GBAs. Very few people managed to play four-person multiplayer at the time. And until now, even emulating it locally with any stability was almost impossible.
The integrated mGBA update allows Dolphin to emulate five consoles at once, with the processors in lock-step. Couple that with the existing delay-based netcode, and their excellent use of STUN for NAT traversal, and four people can collectively emulate twenty consoles at once, finally bringing Four Swords Adventures netplay into reality. It's astonishingly good. We are living in the future.
I think the next thing I would like to do is recreate Zelda Bomberman using WebRTC. It wouldn't be too hard to reimplement it using a client/server model, but for an interesting challenge we could attempt a four-way full mesh topology. Each player would send their inputs to every other player at once. It might work! We shall see.