
infrabuck
10 May 2017Progress: Complete
Infrabuck is a Windows Brainfuck compiler which accepts brainfuck and spits out lightweight, fast .EXE files.
Download source code and compiled binaries here.
BrainFuck
...is a simple programming language with just eight instructions. Despite this, it's Turing Complete. The name derives from how even relatively simple tasks quickly become fiendishly difficult.
Compilers
...translate one programming language into another. Computers generally can only read one language: architecture-specific machine code. In the case of the laptop I'm writing this on, it's an Intel 64-bit processor, but if you're reading this on a phone you're likely using an ARM processor, which has a totally different instruction set.There are two ways of getting a programming language to run – interpreting, sometimes called a virtual machine or emulator, which essentially has a big switch statement which looks at every instruction and acts accordingly; and compiling, where the code is translated into the native machine code.
Interpreters are a lot easier to make than compilers, but they're vastly slower when it comes to running the program.
Since it's the kind of quirky thing that entertains me, I've made many brainfuck interpreters on different platforms, for fun. But in actual fact, Brainfuck was designed as a language that's very easy to compile. I had never written a compiler before. Until today!
Assembly
...is a series of mnemonics that corresponds directly to machine code. It's as low-level as it's practical to be, and I'm a big fan of it for embedded systems, especially when there's no operating system involved. Most compilers are not very good, and if you write the assembly yourself, you usually end up with a much faster and more efficient program. But there's a barrier to writing assembly on a big platform like Windows – you need to know an awful lot about how the operating system, and particularly the Windows API, works. The other day I had a bit of fun playing round with the Windows API in C, and now I'm feeling a little more confident.To compile C, I'm using lcc-win32, and to assemble assembly, I'm using FASM.
Javascript
...is my favourite scripting language because of its universal cross-platform support. Of course I've written a few interpreters in it, here's one.That interpreter is fairly slow because it's double-interpreted. Javascript has a switch statement for each instruction, but javascript itself is interpreted also. But in modern browsers, we have what's called just-in-time compiling. This compiles the code and runs it immediately. The disadvantage is that the compilation must be fast enough (simple enough) to run in real time, but we get the dual advantage of faster code while retaining the ability to change things on-the-fly. As a result, these days Javascript is one of the fastest scripting languages around.
So, the wiki page on brainfuck says that instructions can translate directly to C commands. Out of interest, I made a new script, which replaces brainfuck instructions with javascript code (the process is actually simpler than the interpreter), then appends it as a script node to the document, so it runs. This actually works, although it's no longer asynchronous so the browser appears to freeze while it runs. But when it runs, it's fast! Even without optimization, it ran the mandelbrot plotter in just over 9 seconds on my laptop, compared to well over a minute (I stopped counting) in the interpreter. Cool stuff.
The first thing I did towards making a compiler was create a Javascript program which translates brainfuck into x86 .ASM files. These can then be fed into an x86 assembler, like FASM.
An .EXE as we know it is called a "Portable Executable" by Microsoft. There is a lot of overhead in there. Even a hello world program, compiled in C, seems to end up about 3kB. I don't know the spec too well (or even at all, until yesterday) but there are multiple 'sections', which can be executable code, data, resources or import tables. An import table pulls in DLL files in order to call their functions.
It's usually possible to get a compiler to output an .ASM file, but lcc seems to output an inconveniently different syntax to FASM (even with reversed argument order). But after some tinkering I was able to get a simple assembly console application working:
format PE console entry start include 'win32a.inc' ; Import section section '.idata' import data readable library kernel32, 'kernel32.dll', msvcrt,'msvcrt.dll' import kernel32, ExitProcess, 'ExitProcess' import msvcrt, getchar, 'getchar', printf, 'printf' section '.text' code readable executable start: push ebp mov ebp, esp call [getchar] push eax push mystr call [printf] add esp,8 mov esp, ebp pop ebp call [ExitProcess] mystr: db "You typed 0x%2x",10,0
which assembles to this glorious little program:
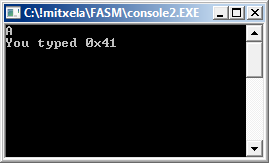
It takes keyboard input and outputs a hex value.
The first half of the code is all directives about what goes into the exe file. 'PE console' is our command line, Portable Executable format. "start" is my label at the first line of code, which is pointed to by a field in the header. 'win32a.inc' is a bit like windows.h, but doesn't actually translate to any code as far as I'm aware, just definitions.
The import section brings in ExitProcess, without which our program would hang at the end, and our IO functions. Importing getchar and printf, which we're familiar with from C, turned out to be easy, and means outputting a number as hex is a piece of cake.
It's apparently the etiquette that every program or routine should preserve the stack pointer on starting, and restore it at the end. To be clear, in this syntax, the first argument is the destination, and the second argument is the source (opposite to what lcc was using, grrr). By convention, when you call a function, its return value is in the register eax. The arguments to the function are pushed onto the stack before calling it, so afterwards we have to add to the stack pointer to restore it (We're 32-bit here, so two arguments means 8 bytes).
Square brackets around a register or label use it as a pointer, much like the & symbol in C. Anything followed by a colon (:) is a label. The label at the end points to our string, which is included as data in the code section. Really I suppose it should have gone in its own data section.
Fantastic, so to produce a simple compiler we need to come up with blocks of assembly instructions that correspond to brainfuck operations, and then it's just a matter of search-and-replace! I used the register ebx as the pointer to memory, so the > and < instructions become inc ebx and dec ebx, while the + and - become inc [ebx] and dec [ebx].
The comma needs to call getchar, which destroys the ebx register, so we have to push it and pop afterwards:
push ebx
call [getchar]
pop ebx
mov [ebx], al
al is an 8 bit register which points to the same memory as eax. So getchar returns in eax, but the mov instruction now only shifts the lowest 8 bits. Since the memory is (I decided) an array of 8 bit values, moving the full 32 bits would wipe the 3 cells preceding it.
Dot (putchar) is called in much the same way, but the loop instructions are where it becomes complicated. If the cell is zero, the opening loop must jump to the end, and if the cell is non-zero, the closing loop must jump to the beginning. In the interpreter, at an opening bracket it has to read forwards in the program, keeping track of 'depth' every time another loop opens, until it finds the corresponding closing bracket to jump to. For our search-and-replace ASM construction, we can use labels. This means the actual jumps in the compiled code become almost instantaneous, instead of having to iterate.
With that, our Javascript Brainfuck-to-x86-ASM compiler was functional. But there's one more thing: optimization. I don't plan on making an amazing optimizing compiler, but there's one optimization that's silly not to do. In Brainfuck you often see long strings of "++++++++++" or ">>>>>>>>>" which can trivially be replaced with single instructions in x86, providing a big speed boost and a reduction in file size.
Here it is:
Paste the assembly output into FASM and it should produce a perfectly working .exe file.
To Exe Files
Depending on an external assembler is quite frankly a cop-out. The next step is translating those instructions into op-codes. Unfortunately we've got a few more hurdles to leap now. Labels make it very easy to jump to certain addresses, we'll now have to manage this ourselves. Also, FASM seamlessly takes care of distance – short jumps produce 'near' op-codes, longer ones use 'far' opcodes which have a 32-bit offset. These variable length op-codes make calculating the distances all the more effort.To simplify things, I opted to always give the [ instruction a 'far' jump. This slightly pads the code size, but means we can insert dummy bytes, push the address onto a stack, and when we reach the closing bracket we will know both addresses, so we can calculate the distance and fill in the jump details for both. The closing bracket hence can make use of 'near' jumps. (To use foward 'near' jumps would require multiple passes (and indeed FASM iteratively passes the file until all labels are resolved) but I'm not convinced the reduction in code size is worth it.)
There's also a whole lot of header data to fill in. I tried looking for references for this, but most of them were pretty difficult to make sense of. Some sources claim the checksum algorithm is proprietary (??) and others say it isn't used. There is data in the checksum field that FASM produces, it changes from program to program, but if I manually edit it to something different, the .exe still runs.
This image was found on a blog, which didn't give a source for it, so I won't either:
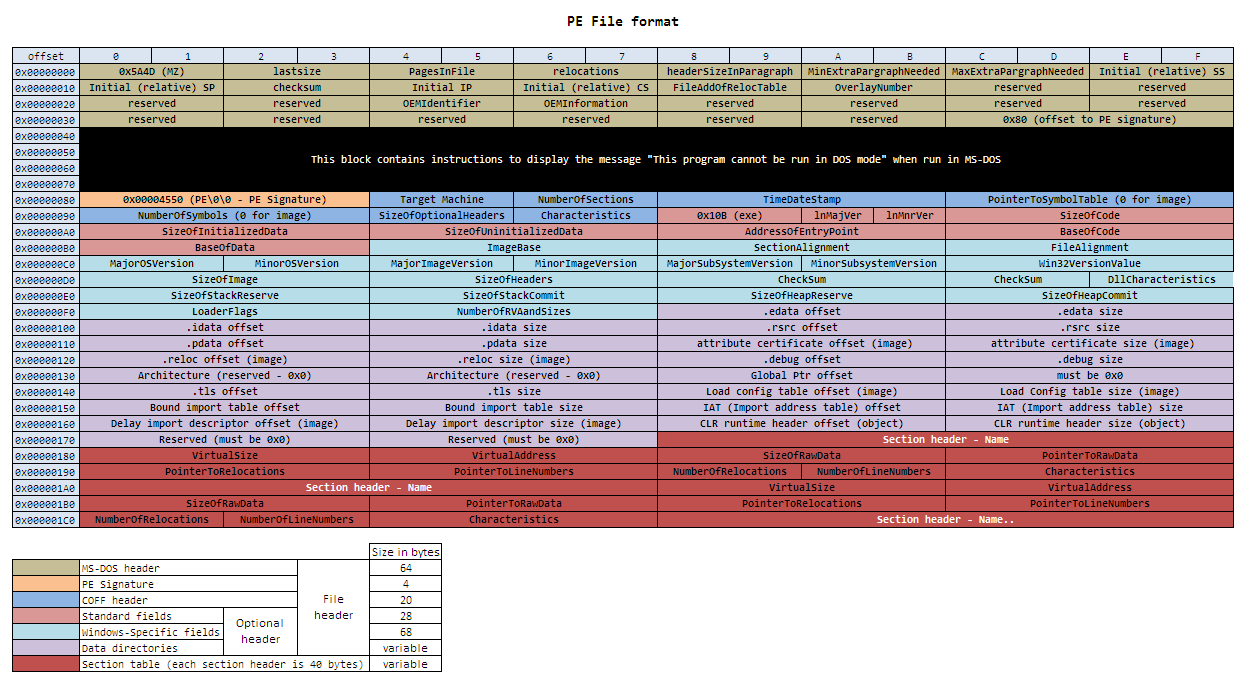
The timestamp is easy. The other fields... well, the easiest thing to do is just look at what FASM is outputting and copy it. I wrote a few assembly files of different lengths (the 'repeat' directive is useful) and watched how the fields changed. We only need to reverse-engineer the bare minimum in order to get a working exe file.
I used lcc to produce the compiler, about 200 lines of C code. It's now on github for you to enjoy. There's no limitation on the pointer, if the brainfuck code tries to access a negative index windows will probably throw a seg fault ("asdf.exe has stopped working, windows is searching for a solution to the problem"). The upper limit is 32768 and the cells are 8-bit.
To use, call the program like
bf.exe program.bf output.exe
Then run output.exe, and be amazed.
I must say it's remarkably satisfying. The first hello-world in compiled brainfuck was most entertaining. Additionally, and as we would hope, really intensive programs like the mandelbrot plotter run super quick (1.4 seconds on my machine).
To do: Add a compile-time flag to set the cell size. Would have been quite easy if I'd thought of it at the beginning. Some programs depend on bigger cell sizes to work, but really I feel brainfuck is very much an 8-bit affair.
IDE
We've written our own command-line compiler. Now, hoho, haha, let's write an "IDE" for it!A debugger with memory inspection, breakpointing, run-to-cursor and so on would be quite useful. But I'm not interested in making that (yet). I just want a glorified version of notepad that invokes the compiler. After my first attempt mucking about with the windows API (making a calculator) I feel this is the perfect opportunity to further develop our err... for further mucking about.
Notepad is just a big "EDIT" window (a textarea) with some extra stuff. The file/open/saveas dialogs are standard calls. This is pretty standard stuff and there are lots of tutorials about it. I took one of the first search results ("theForger's Win32 API Programming Tutorial") as a starting point. On window resize, the edit box is resized accordingly. And a resource file is used to manage the file menu.
It's interesting to see what a default edit box can and can't do. Ctrl+C will copy the selected text, Ctrl+V will paste it, but Ctrl+A won't do anything. But there is a select-all option in the default right-click context menu. Similarly we want Ctrl+O, Ctrl+N, and Ctrl-S to invoke the file menu items, so the first thing to do is add these using "accelerators". Accelerators can be loaded from the resource file and seem pretty straight forward, just a list of key combinations and IDs. We give them the same IDs as the file menu is using. We also need to add a line to our message loop, calling TranslateAccelerator(). As you can probably imagine, this looks at keyboard events coming in, and if they match the keystrokes listed, sends the appropriate WM_COMMAND message. For select-all, in our switch statement we send an EM_SETSEL message with parameters 0 and -1.
Next thing to add is accepting a file-open argument. When you drag a file onto an application icon, or select "open with", the filename gets passed to the program as its command-line argument. We don't have the usual argc and argv in our main function, but WinMain has an lpCmdLine argument which contains the filename passed. I copied this into a global variable, then in WM_CREATE, after we've made the edit box, we can load the file if present.
There are other reasons to remember the working file name. We want an option to save without a save-as dialog each time. We also need to come up with a suitable filename for the output of the compiler. Another global variable we need is to keep track of whether the file has changed since it was opened or last saved, and if so, we can put a little asterisk in the title bar, and give warning messages before closing or opening a new file. We have to be sure to pay attention to the difference between 'no' and 'cancel', but it's all pretty simple stuff.
I noticed right away that if you alt-tab onto the window, you can't just start typing. In the WM_ACTIVATE event we need to explicitly SetFocus() back to the edit box to fix this. Other simple things I added: an icon (I just took the mitxela.com favicon because I'm incorrigibly lazy), loaded as a resource; and a status bar, which is – you guessed it – another type of window. I set the text, when needed, to the length of the text selection, because that's invaluable information when writing brainfuck. When to update the status bar is a difficult one. I ended up having to call our UpdateStatusBar() function on all keydown and keyup events, and also on WM_MOUSEACTIVATE and WM_CTLCOLOREDIT. The latter two are needed for the status bar to reflect text selections done using the mouse.
All right, now for the big kahuna...
Invoking the compiler from the IDE
It's not as simple as justsystem("bf.exe"); or ShellExecute() or whatever. We want to invoke the compiler in the background, capture its standard output and if there were no errors, then we can execute the resulting file. CreateProcess() is a more flexible way of launching another application. Its last two arguments are references to structs: StartupInfo and ProcessInfo. While the process is running, we can pass the process info to WaitForSingleObject(), which will halt our code until the compiler has finished. This does mean the application will freeze if the compiler takes a long time, but even on the longest programs it seems almost instantaneous. Perhaps next time we can make a loading-bar dialog. There's also a Creation Flags parameter to CreateProcess, in which we can signal the process not to create a window. Without this, the instant compilation means a console window flashes on the screen for a split second, which is just annoying.
One member of the StartupInfo struct is hStdOutput, a handle to its standard output. Sounds good, but to this we need to assign a handle populated by the CreatePipe() function. And this function, in turn, takes a struct argument of type SECURITY_ATTRIBUTES. This whole struct is just to let us set a boolean, bInheritHandle = true.
It's rather a lot of code for the simple task of redirecting a process' output, but now that we have a handle to it, after we've called CreateProcess() and waited for it to terminate, we can read the handle with ReadFile(). The return code of the compiler, as is customary, is zero on success, so we can take action according to the response of GetExitCodeProcess(). If it failed, we read the pipe and display the error in a message box. If it succeeded, we can now create another process, launching the newborn application, this time letting it form a new window and existing on its own.
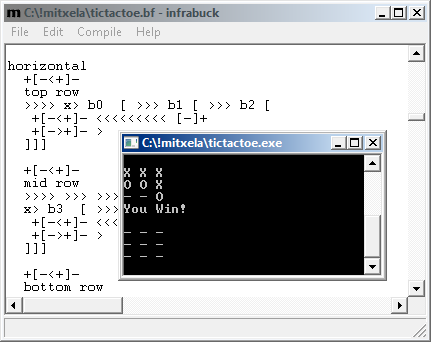
Most excellent. We have learnt about exe files and windows programming and created a tool which may not be entirely useless to potentially more than one person. Potentially. I, for one, have enjoyed the journey, regardless of how pointless it was, and though I'm now going to go off and do something completely different, I may return and add some more features, possibly even useful ones. Maybe!
The source code and the executable download is all on github.