
Human-readable 2D Barcode
20 Mar 2020Progress: Concept
QR codes are great but if you have a bunch of them, it can be a pain to remember what they say. Admittedly it's not that much hassle to scan them to find out, but it's a lot less convenient than, for instance, conventional barcodes which have the digits printed underneath. I also have trust issues, and end up scanning repeatedly with different devices, because without personally checking it, how can I believe that's what it really says? But that's by the by.
And there's another thing. Those numbers under a conventional barcode, who's to say that they're correct? In fact you could double your data density by storing different information in the barcode to the string underneath. Essentially, I have great difficulty accepting unintelligible markings on paper that are meaningful to computers.
You might ask, in this day and age, do we even need barcodes? Optical character recognition (OCR) is so good that we should just as easily be able to "scan" a block of printed text in the way that we scan a barcode. The answer is in redundancy and error-checking. OCR makes mistakes, and it may not even be clear that a mistake has been made. QR codes contain enough redundancy that they will still scan correctly even with a corner torn off. In the most extreme cases they will fail to scan, which is more desirable than scanning in the wrong data.
The error-correction of a QR code is so great that some people stick images and logos over the top of them, knowing that they will still scan, making a symbol that can be understood by both human and machine. But again, both readers are looking at different information, that happens to be smooshed together.
At this point you should be able to guess what my proposal is. A human-readable barcode made up of written text, surrounded by fiducials, timing information, and error checking. The information would be immediately obvious to both a human and a machine, with the auxiliary info letting you check its integrity and recover lost characters.
In detail, the content would be escaped as some variant of quoted-printable, so that it can be represented as printable ascii characters. The font would be OCR-friendly, such as the type used on cheques, to maximise machine readability. The fiducials or corner-markers would be big and obvious in three corners, much like the double-bordered squares in a QR code. The timing information is simply a dotted line between the fiducials to set the grid-size. The text would be printed inside the grid in a monospaced font, aligned to the grid, and around the bottom and right-hand edges the last row/column would contain a series of human-readable numbers.
These numbers would be a checksum for each row/column of the grid, much like a Hamming code. This provides enough info to locate a mis-read character, and potentially recover its value, but doesn't come close to the error-checking of a QR code. The reason for this choice is simple: if one were so inclined, the checksum for each row/column could be calculated with a pencil and paper. So the redundancy is human-checkable, too.
The mockup image for this idea probably bears little resemblance to what the Human-Readable 2D Barcode would look like:

But when I first toyed with this idea (July 2019) I produced some more serious mockups. Using Excel, no less.
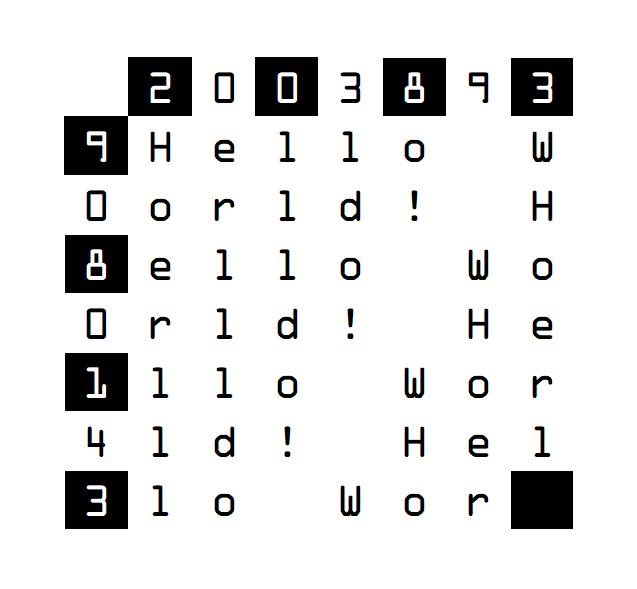
The checksum algorithm is just the sum of the ascii codes modulo ten.

It's still not clear if this amount of "timing" info would be sufficient and perhaps there should be a way to indicate EOF.

If I feel a burst of enthusiasm I will hack together a scanning program with OpenCV and we can see how well they perform.